A dataset with political datasets #4
A quick update on my dataset with political datasets, PolData. I wrote the last post with updates on the project back in 2024, and a few things have happened since then. I started the project back in 2017, and I believe the overview of political datasets is in a better shape than ever.
First, I can recommend the great chapter 'Data and data sets' by Rahel Freiburghaus in the book Handbook of Comparative Political Institutions. The chapter uses PolData as a starting point to zoom in on 13 datasets in detail on political institutions in comparative politics. I appreciate the way PolData is being used in this context, and here is a good example of the description:
Hence, the PolData GitHub repository enables the researcher not only to narrow down political science data sets into thematic categories, but also to make well-informed, inevitable data selection choices. PolData is a collaborative effort, with scholars and users worldwide invited to provide updates, hints, and suggestions for novel and emergent political data sets to its owner, Erik Gahner Larsen. This approach acknowledges the ever-expanding and dynamically evolving ‘data set landscape’ and ensures that the repository stays relevant well beyond the present day. Hence, researchers are encouraged to consistently draw on the most recent version of the PolData GitHub repository.
I am happy to see researchers rely on my work in their own work, including when academics are using it in their teaching (e.g., to help students explore potential data sources for their projects). That being said, while I do my best to keep the project up-to-date and add new data sources, it is important to keep in mind that I am not in academia anymore or actively keeping myself updated on what is happening within the domain of political science.
From 2018 onwards I have added information to each entry in the overview of when it was most recently revised in the overview. If a dataset is no longer available, I remove it from the overview (my own dataset with Danish election polls is one such example). The figure below shows, for all datasets in the overview, when the most recent revision was made for each dataset.
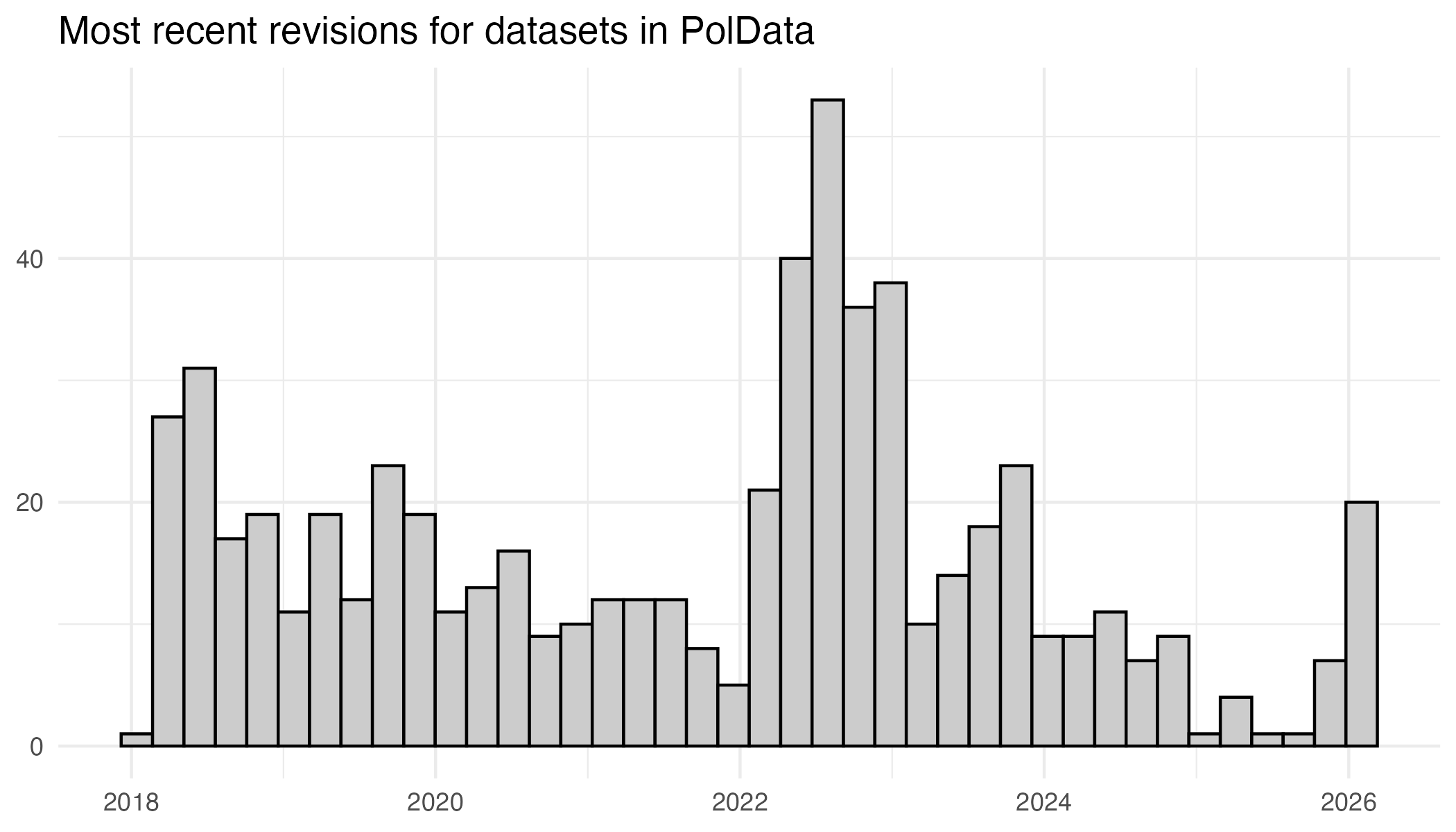
It is easy to see that it has been a while since a lot of the entries have been revised. One potential way to contribute to the project is to not only add new datasets to the overview that I have missed, but also to add pull requests with any relevant updates to the entries that have not been updated for many years. In other words, if you see any outdated information in the overview, feel free to contribute.
There is now also information for all entries in the overview of the geographical coverage. Out of the 619 datasets in the overview, 298 of them cover the main regional groups of the world (as per the United Nations Regional Groups of Member States). As per tradition in political science, most of the datasets are comparative in nature, covering multiple countries. 448 of the datasets includes data from multiple countries, and 171 includes data from a single country. The figure below shows what countries are being covered by the datasets including data from a single country.
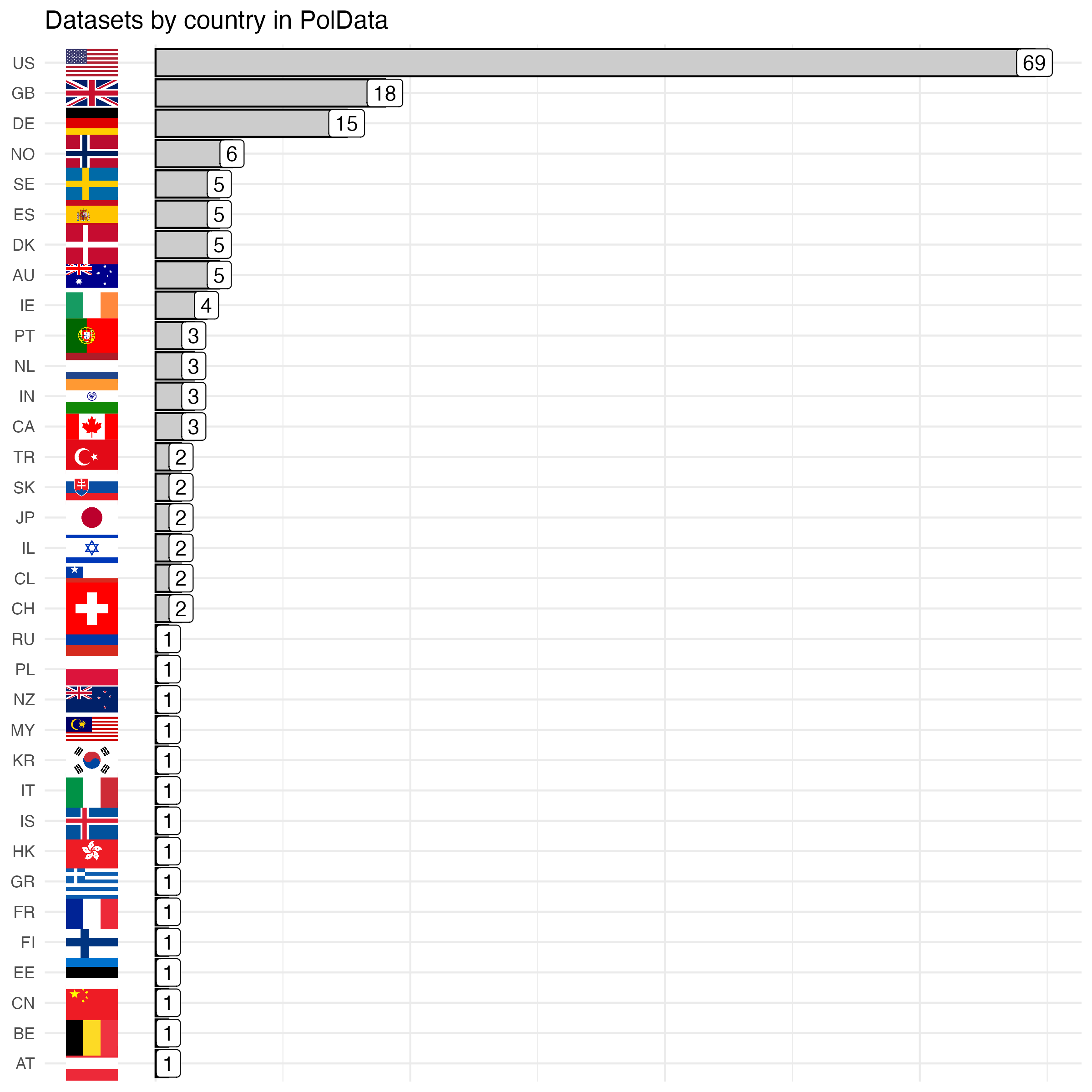
Unsurprisingly, we see that a lot of the datasets cover the United States. Accordingly, another good way to contribute to the project in the future will be to add datasets from countries that are not currently included in the overview. I am confident that there is a lot of relevant data of interest for political scientists out there that is currently not included here.
I guess it is somewhat a surprise to me that the resource is still being used to this day, and I will most likely only stop to maintain the overview the day that I know that nobody finds it useful. I started the project prior to LLMs, and I can imagine that any decent AI agent will do a good job at finding relevant data today. Of course, this repository might be one of the resources being used, and one aspect I enjoy of this project is that it is indeed started prior to any AI and the like (in other words, I am not sure I would have started a similar project today, even if I was working in academia - or, especially not if I was working in academia).
Again, do feel free to contribute to the project. I have a bias towards publicly and freely available datasets in the overview, and if you decide to contribute, I will appreciate it the most if any new datasets to the overview are publicly and freely available.