Meningsmålinger for Jyllands-Posten #2
I 2022 havde jeg et fortræffeligt samarbejde med Jyllands-Posten, hvor de formidlede resultaterne af mit vægtede snit af meningsmålingerne. Det bidrog efter alt at dømme til et større fokus på tendenser i meningsmålingerne snarere end (flygtige) enkeltmålinger. Det vægtede snit klarede sig overordnet godt ved valget, hvilket blot var udtryk for, at meningsmålingerne generelt klarede sig godt (hvis meningsmålingerne systematisk tager fejl, vil et vægtet snit som bekendt også tage fejl).
Det var desværre ikke alle analyseinstitutter, der så en fordel i at have et samlet overblik over meningsmålingerne. Især Politiken og TV 2 har det bedst med, at der er fokus på sensationelle enkeltmålinger, så de jævnligt kan publicere nye men ofte fejlagtige artikler (jeg har dokumenteret talrige eksempler på især TV 2's problematiske dækning i mere end et årti, se eksempelvis her). På baggrund af henvendelser fra Megafons advokat valgte jeg således at lukke Politologi.dk ned efter folketingsvalget i 2022 (jeg skrev dengang et mere detaljeret indlæg om, hvorfor jeg lukkede siden ned).
Jeg er et andet sted i tilværelsen i dag end da jeg startede Politologi.dk, både personligt og professionelt. Jeg har ikke længere samme interesse i at dykke ned i hver enkelt meningsmåling, der bliver offentliggjort, og jeg har ved flere lejligheder opfordret folk til at lave et alternativ til Politologi.dk. Denne slags projekter vil dog altid være præget af at tage en masse tid og lidt penge (primært på at holde en hjemmeside kørende, men også potentialet for at blive sagsøgt for et klækkeligt beløb), hvorfor jeg om nogen forstår, at folk ikke har travlt med at skabe en efterfølger til Politologi.dk.
Jyllands-Posten har dog heldigvis en ihærdig interesse i at hæve barren for dækningen af meningsmålingerne, og jeg er glad for, at vi kunne have en aftale om, vi kørte snittet videre hos dem under denne valgperiode. Politologi.dk kørte udelukkende efter de forhåndenværende søms princip, og Jyllands-Posten er langt bedre stillet til ikke alene at formidle snittet, men også at sørge for, at det rent faktisk kommer bredt ud (og fungerer som et reelt supplement til enkeltmålingerne). Det vil sige, at mit vægtede snit af meningsmålingerne udelukkende blev formidlet på Jyllands-Postens hjemmeside, og jeg havde ingen interesse i at køre snittet sideløbende på Politologi.dk.
Snittet har været at finde på jp.dk/snittet. Du kan læse mere om lanceringen af snittet her samt om metoden bag snittet her. Du kan finde et eksempel på en artikel, der bruger snittet, her. Og her er det endelige snit, da de seneste meningsmålinger var blevet inkluderet på valgdagen:
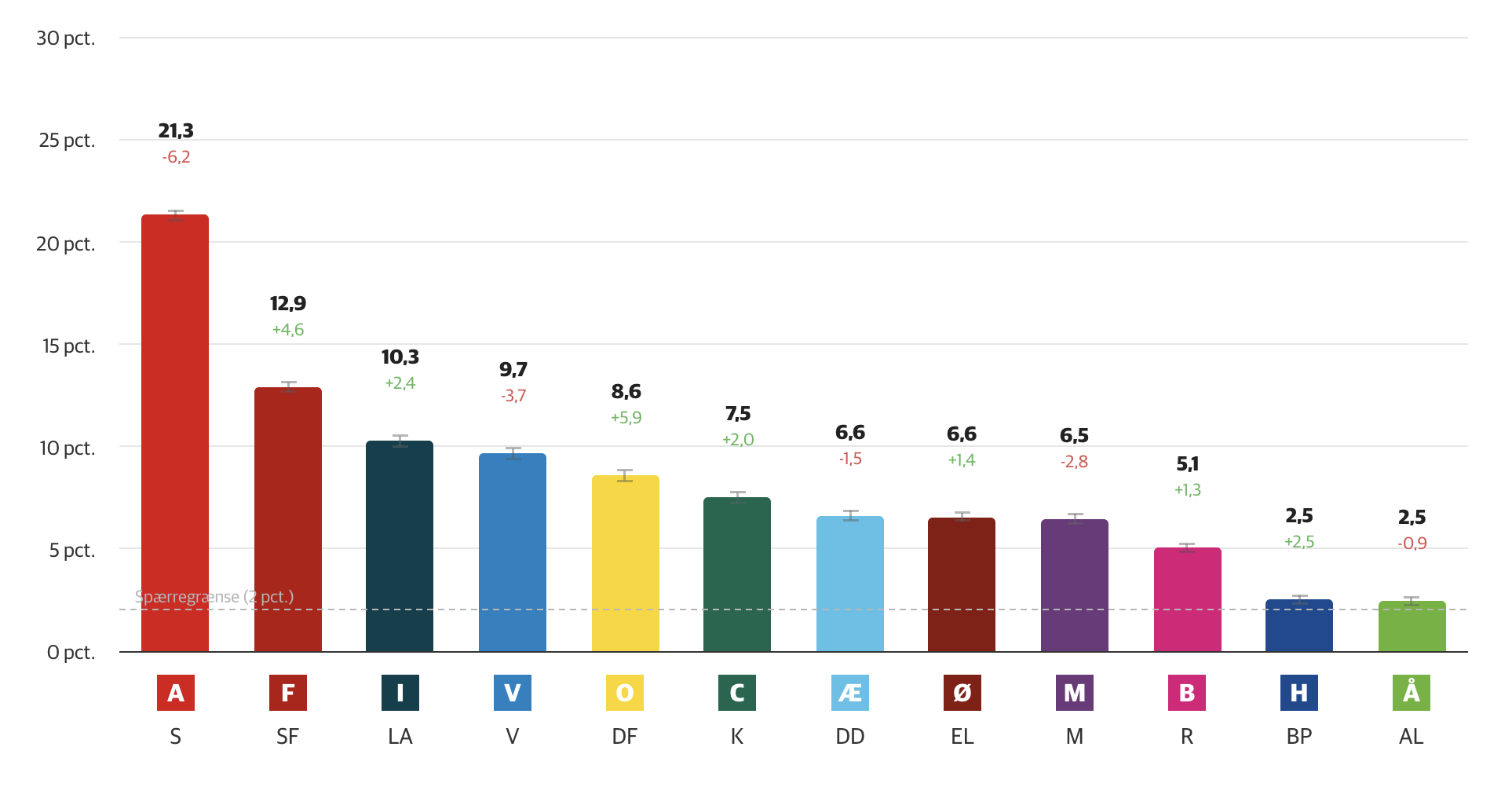
I dette indlæg bringer jeg et par ekstra detaljer omkring snittet og fremgangsmåden, der kan have interesse for meningsmålingsconnaisseurerne derude. Fokus vil selvfølgelig være på det netop overståede folketingsvalg. Dette bliver et lidt længere indlæg, da jeg op til og ved tidligere folketingsvalg har haft for vane at skrive et tocifret antal indlæg omkring meningsmålingerne (både generelt og i forhold til enkelte målinger og historier). Jeg har desværre ikke haft tiden til at følge med i dansk politik de seneste år, og der er med sikkerhed en masse dårlige og gode pointer, jeg har overset hist og her, som under tidligere omstændigheder ville have affødt diverse indlæg.
Den generelle pointe, jeg vil fremhæve, er, at meningsmålingerne havde et ganske fornuftigt folketingsvalg i 2026, og JP-snittet havde af samme grund også et fint folketingsvalg. Overordnet betragtet kom JP-snittet tættere på valgresultatet end enkeltmålingerne og DR og TV 2's exitpolls. De respektive enkeltmålinger og exitpolls havde hver især forskellige målefejl, der blev reduceret i JP-snittet, og for de partier, hvor målingerne ramte bedre, var der stadig større fejl for andre partier, der gjorde, at JP-snittet, når alt kommer til alt, klarede sig bedre. Jeg tror ikke, at dette skyldes en bedre metode, og det er relativt få decimaler, der skulle have ændret sig, før JP-snittet ikke ville være i top (med andre ord kan man overveje den statistiske usikkerhed i målefejlene).
Folketingsvalget 2026
Det var en overraskelse for mig, da Hans Engell den 25. februar udtalte, at et valg kunne være om hjørnet, og enten blive udskrevet torsdag den 26. februar eller tirsdag den 3. marts. Jeg havde nogle idéer til, hvordan snittet kunne blive forbedret yderligere op til et valg, men noget som jeg nok først ville have tid til at arbejde på i løbet af sommeren. Men torsdag den 26. februar kunne man således se følgende historie på Ekstra Bladet og de andre medier:

Heldigvis havde vi et setup i stand, der gjorde, at Jyllands-Posten var klar til at dække valget uden problemer og uden at jeg - i princippet - ville skulle røre en finger. Vi lavede blot en mindre justering, der ikke ændrede resultaterne af snittet, men gjorde, at snittet ville være responsivt i løbet af valgkampen, skulle der ske uforudsete og store forskydninger i opbakningen til partierne. Og så fik snittet lov til at køre helt af sig selv op til valgdagen.
Hvor mange meningsmålinger så vi i valgkampen?
Før vi kigger på, hvordan snittet klarede sig, er det godt at forholde sig til, hvilke og hvor mange meningsmålinger, der blev brugt fra valgkampen. Meningsmålingerne kan fylde meget i en valgkamp, men hvis du mener, at der var mange meningsmålinger i denne valgkamp, har du med al sandsynlighed glemt, hvordan det var for år tilbage. I nedenstående figur ser vi 1) antallet af meningsmålinger der blev foretaget i løbet af de seneste fem valgkampe (fra 2011 til 2026) og 2) antallet af meningsmålinger fra de respektive institutter i løbet af den netop afsluttede valgkamp.
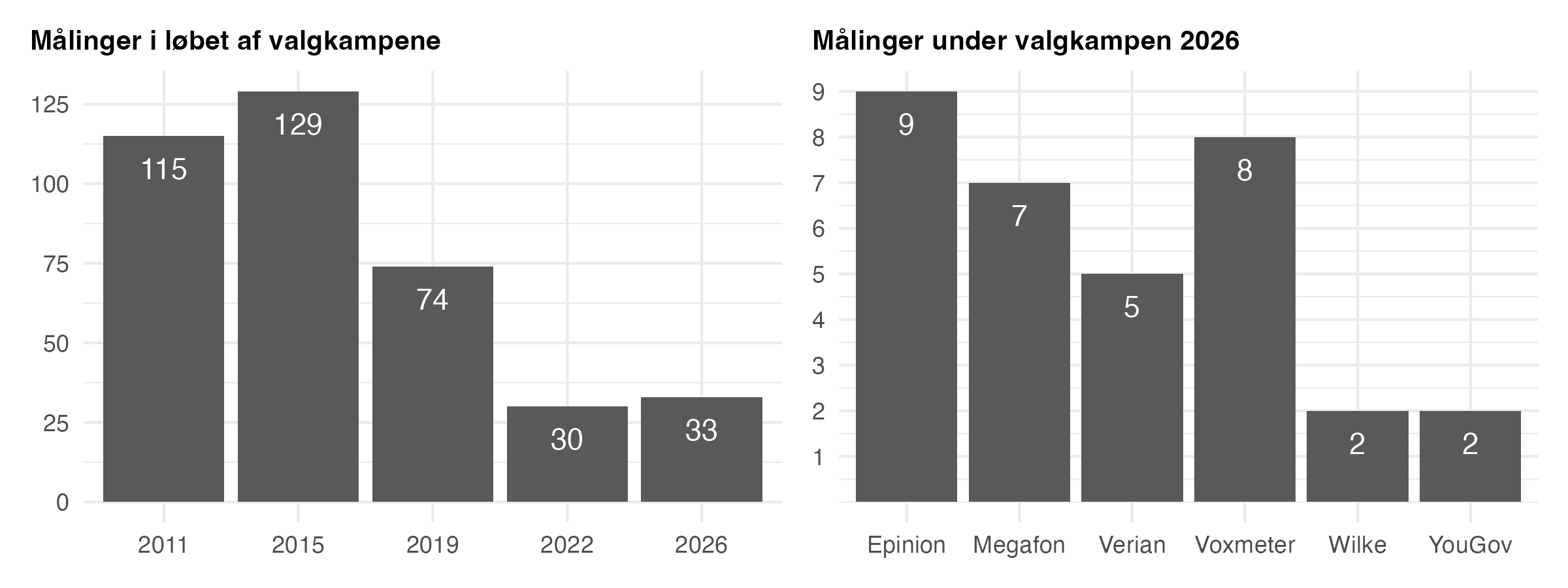
I 2015 så vi hele 129 meningsmålinger, hvilket er næsten fire gange flere end under denne valgkamp. Der var en stor ændring i antallet af meningsmålinger fra folketingsvalget 2015 til folketingsvalget 2019. Jeg husker tydeligt valgkampen i 2015, hvor jeg dagligt tilføjede 5-6 meningsmålinger til mit datasæt med meningsmålinger. I 2019 var der langt færre meningsmålinger, hvilket også var noget, jeg pointerede, da jeg forud for valgkampen var gæst i Presselogen og gav medierne ros for, at have færre meningsmålinger samt fokusere mere på vægtede gennemsnit.
Det giver selvfølgelig også nogle udfordringer for et vægtet snit, hvis der er få meningsmålinger. Vi så 33 meningsmålinger i løbet af denne valgkamp, men det betyder ikke, at der er 33 unikke meningsmålinger i gennemsnittet. For det første har TV 2 og Megafon stadig en stor interesse i at kæmpe for, at der kun er fokus på enkeltmålingerne, så Megafon indgår ikke i snittet. Så dette reducerer antallet af meningsmålinger fra valgkampen i snittet fra 33 til 26.
For det andet er det ikke klart, hvornår en meningsmåling er én meningsmåling. Flere institutters meningsmålinger i løbet af valgkampen har et overlap i de svar, der indgår. Det vil sige, at data, der indgår i én meningsmåling, også kan være brugt i en anden meningsmåling. Hvis vi eksempelvis ser på YouGovs to meningsmålinger fra denne valgkamp, var den første foretaget i perioden fra 1. til 18. marts, og deres anden (og sidste) meningsmåling i perioden fra 5. til 23. marts. Giver det mening at se dem som to meningsmålinger, når der er et større overlap, end forskelle i indsamlingsperioden?
I det vægtede snit ser vi dem som forskellige meningsmålinger. Da vi bruger data fra hele valgperioden i snittet, og ikke kun data fra valgkampen, har vi - til trods for mindre data sammenlignet med tidligere valg, stadig fint med data til at sige noget fornuftigt om, hvor partierne sandsynligvis står, når vi tager forskelle mellem institutterne i betragtning.
Hvordan klarede snittet sig?
Jeg vil her se nærmere på, hvordan snittet klarede sig ved dette folketingsvalg. Dette er relativt simpelt, da vi blot ser på, hvor tæt meningsmålinger, exitpolls og snit kom på det endelige valgresultat (jeg lavede lignende analyser ved folketingsvalget 2019 og folketingsvalget 2022). For et mere generelt indlæg om, hvordan meningsmålingerne klarer sig i et komparativt perspektiv, se dette indlæg.
Det giver mening at sammenligne det vægtede snit med enkeltmålingerne og de respektive exitpolls. Der er foruden JP-snittet også Altinget-snittet, hvor vi kan bruge tallene fra det sidste vægtede snit forud for valget. Det er dog vigtigt at holde for øje, at dette snit er fra den 22. marts og dermed ikke helt opdateret, hvorfor jeg opfordrer til, at man ikke laver direkte sammenligninger med JP-snittet og de andre estimater.
Når det kommer til exitpolls, har vi at gøre med en lidt mærkelig situation. Vi har i udgangspunktet to exitpolls, en fra Epinion (for DR) og en fra Megafon (for TV 2). Epinions exitpoll kan findes her. Megafons exitpoll kan findes her, og her er tallene som de så ud på valgaftenen klokken 20:21:
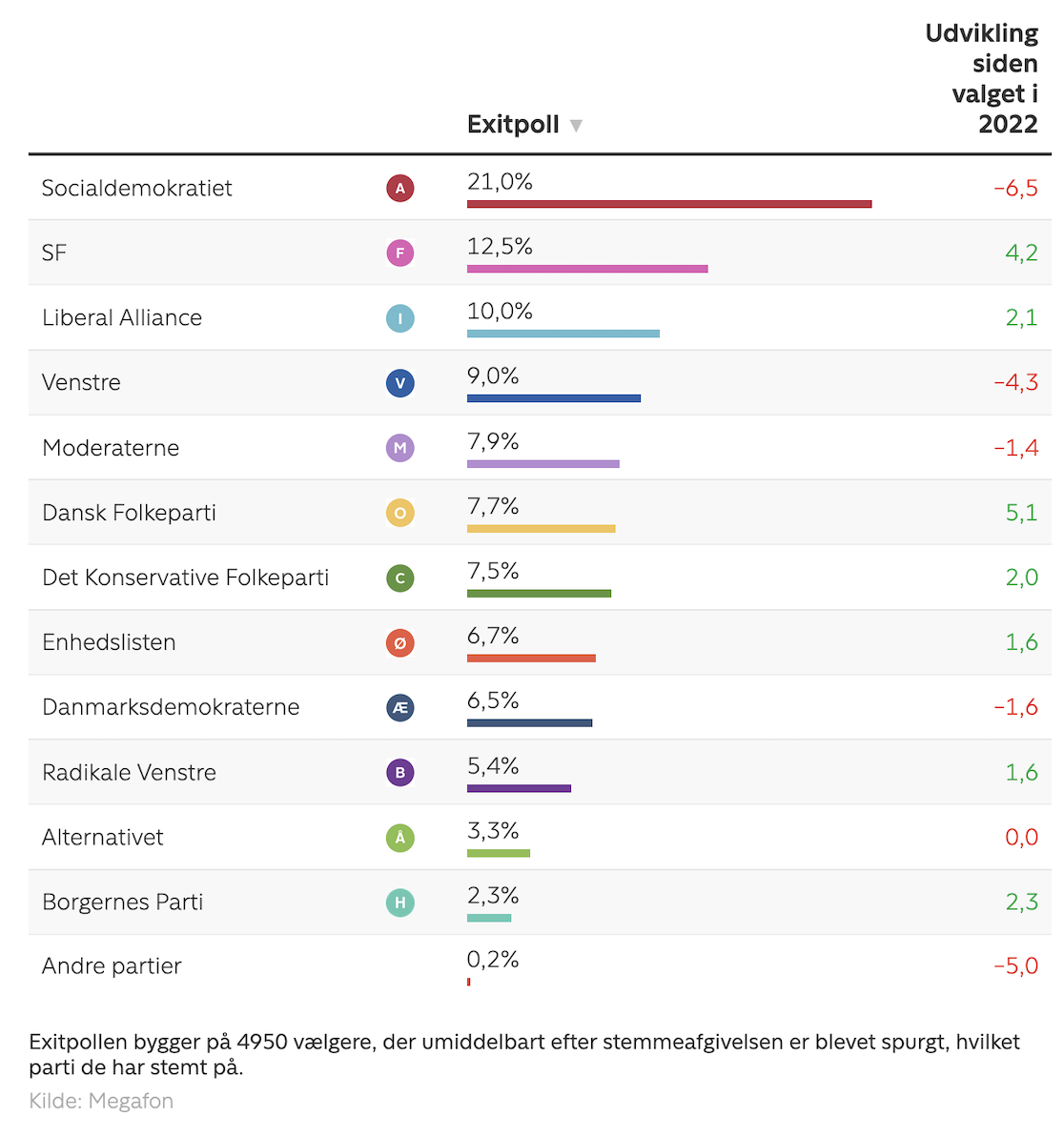
Noget tyder dog på, at Megafon og TV 2 opdaterede deres exitpoll igen, hvilket vi også så under forrige folketingsvalg, hvor de havde to exitpolls. De tal, du ser i tabellen ovenfor, er således ikke de tal, du vil finde, hvis du ser på den pågældende exitpoll nu, hvor tallene er opdateret. Jeg var i stand til at finde endnu en artikel fra TV 2 på valgaftenen, hvor de skriver "Opdateret med seneste exitpoll klokken 20.44.". Vi har derfor at gøre med tre exitpolls, en fra Epinion og to fra Megafon.
I nedenstående figur viser, hvordan alle estimater fordeler sig for de forskellige partier, så vi kan se hvordan enkeltmålinger (●), exitpolls (●) og vægtede snit (■) klarede sig i forhold til valgresultatet (▲). Jo længere et estimat ligger fra valgresultatet, desto dårligere klarede den pågældende meningsmåling, exitpoll eller snit sig.
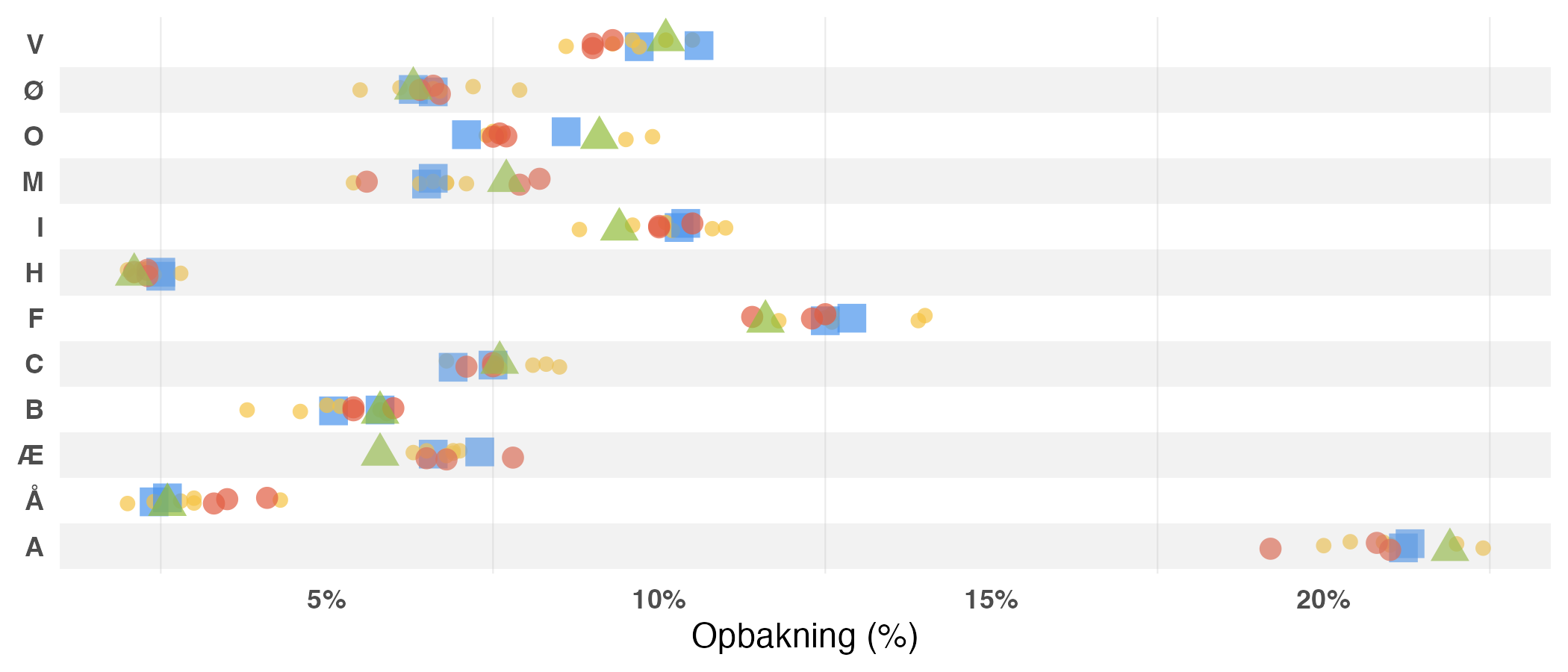
Med undtagelse af Borgernes Parti (H) ser vi variation for alle partier. For Socialistisk Folkeparti (F) og Moderaterne (M) ser vi også, at meningsmålingerne henholdsvist overvurderede og undervurderede de to partier, hvor de to første exitpolls kom tættere på resultatet. For Danmarksdemokraterne (Æ) er det let at se, at alle estimater overvurderede opbakningen til partiet, der endte med at få et dårligere valg end målingerne gav dem. Den overordnede konklusion er her, at til trods for variation på tværs af meningsmålingerne, ser vi, at det endelige valgresultat ligger et sted mellem de respektive meningsmålinger. Dette skaber ideelle betingelser for et vægtet snit.
I den næste figur kigger vi på relationen mellem estimat og resultat for hvert af de respektive institutter og snit. Jo tættere punkterne ligger på den stiplede linje, desto bedre. Vi fokuserer her ligeledes på den gennemsnitlige forskel, hvor lavere værdier er bedre (en værdi på 0 ville indikere, at alle estimater ramte valgresultatet perfekt).
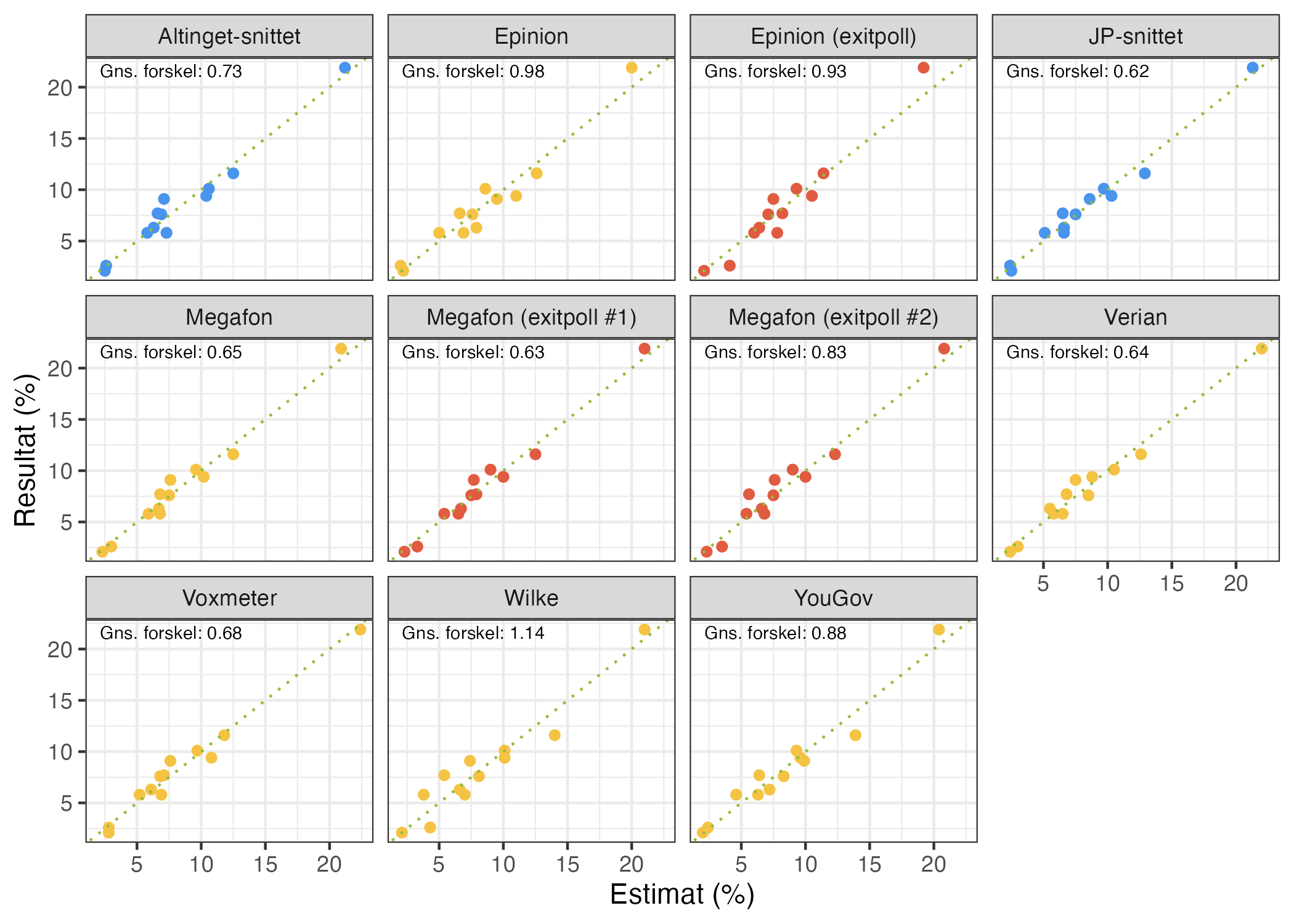
Vi ser den mindste gennemsnitlige forskel for JP-snittet. JP-snittet klarede sig med andre ord bedre end enkeltmålingerne individuelt og de respektive exitpolls. Igen vil jeg undlade at lave en direkte sammenligning med Altinget-snittet. Som jeg pointerede i et indlæg for et par år siden, er meningsmålingerne utroligt gode i en dansk kontekst, og den gennemsnitlige fejl ved de seneste syv folketingsvalg forud for valget i 2026, viste en gennemsnitlig fejl på 0,94. Den gennemsnitlige fejl for JP-snittet ved dette valg var 0,62, hvilket var meget tilfredsstillende. Det er dog også værd at påpege, at målinger fra Megafon, Verian og Voxmeter kommer meget tæt på dette, så det er alt sammen små gennemsnitlige forskelle, vi kigger på her.
En sjov iagttagelse er, at Megafons første exitpoll klarede sig bedre end deres opdaterede exitpoll. Det er en gentagelse af folketingsvalget i 2022, hvor deres første exitpoll også klarede sig bedre end deres opdaterede exitpoll. Min opfordring til TV 2 og Megafon vil være at offentliggøre én exitpoll på valgaftenen, og det virker til, at alt hvad de gør med deres exitpolls efter klokken 20 på valgaftenen ikke er for det bedre.
Overordnet er det som sagt fine resultater, og YouGov annoncerede også, at de var glade for at have en gennemsnitlig fejl på kun 0,88. Det er fint generelt betragtet, men YouGov var ikke blandt de bedste institutter. Det er således interessant, at de institutter, der gennemførte flere meningsmålinger op til og i løbet af valgkampen, havde et bedre valg. Jeg skal ikke kunne udtale mig om hvorfor, men en hypotese kan være, at disse institutter har et bedre overblik over udfordringerne med at nå ud til bestemte vælgere.
Vi skal for en god ordens skyld her også kigge på kvadratroden af den gennemsnitlige kvadratafvigelse. Logikken er, at større afvigelser betyder mere for, hvor godt en måling har klaret sig. Det vil sige, at det er mere problematisk at ramme ét parti forkert med 0,5 procentpoint end fem partier forkert med 0,1 procentpoint. Disse tal er vist i figuren nedenfor.
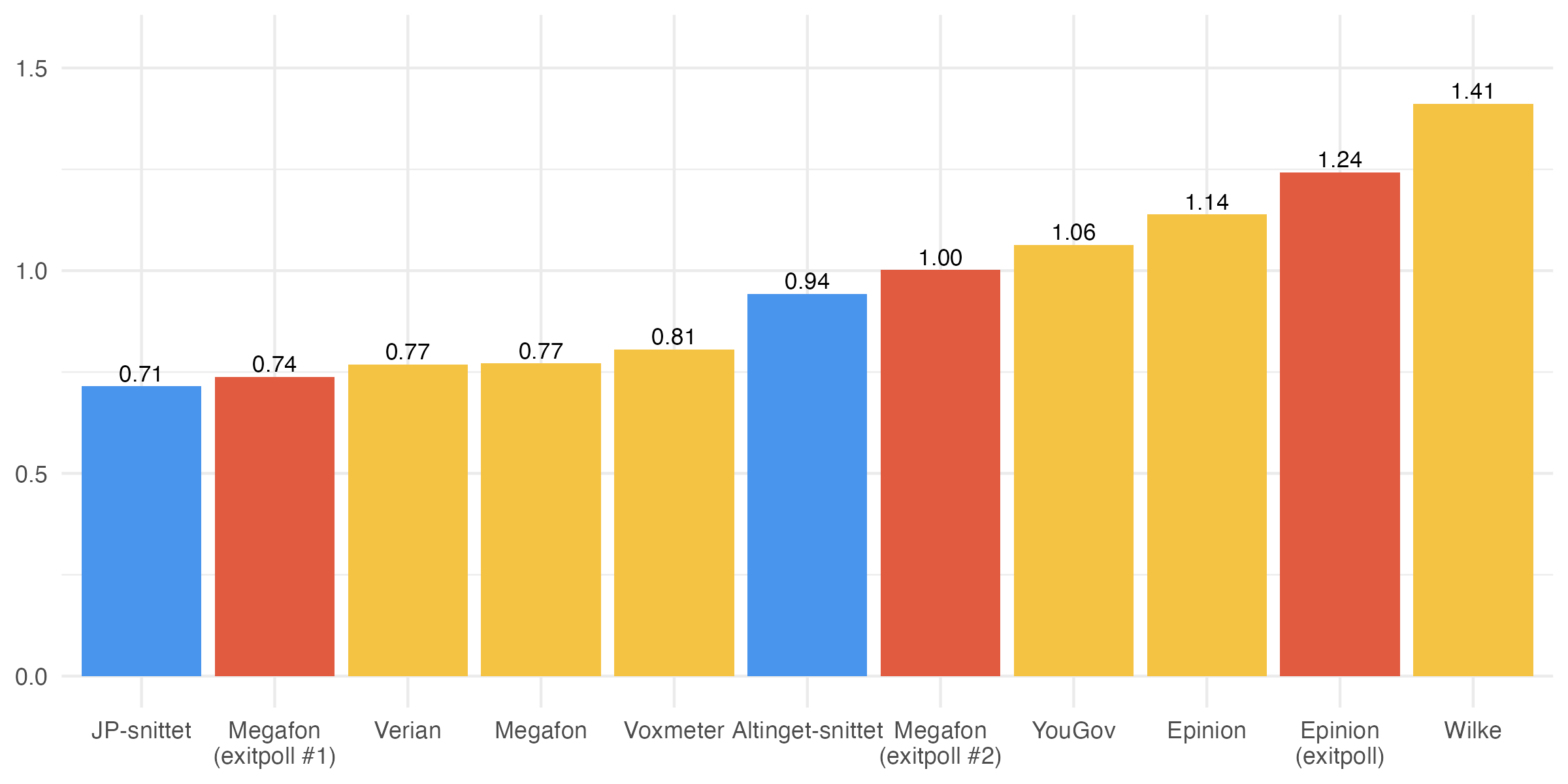
Igen er den overordnede konklusion, at JP-snittet klarede sig ganske godt. Det er ingen selvfølge, at målingerne ville have klaret sig godt, især i en tid hvor der er stor volatilitet på både blok- og partiniveau (som Jacob Christensen også har pointeret her). Det er som det næste interessant, at snittet også klarede sig bedre end begge exitpolls, og især at de fleste meningsmålinger også klarede sig bedre end DR's exitpoll.
Den største forskel finder vi således ikke i en meningsmåling men i Epinions exitpoll. Her ser vi, at Socialdemokratiets opbakning underestimeres med 2,7 procentpoint (partiet ender som bekendt med at få 21,9% af stemmerne men den pågældende exitpoll gav partiet 19,2%). Dette var selvfølgelig også en af hovedhistorierne, der kom ud på baggrund af den pågældende exitpoll. DR har hæftet sig ved at "fortællingen" var rigtig, altså at partiet gik tilbage. Det er i udgangspunktet korrekt, men det er stadig den største individuelle fejl ved dette valg.
Så hvordan klarede snittet sig? Det klarede sig godt. Som jeg sagde indledningsvist, kan et snit kun klare sig godt, hvis meningsmålingerne samlet betragtet klarer sig godt, hvilket var tilfældet ved dette valg. Dette folketingsvalg er med andre ord ingen undtagelse fra tidligere valg, hvor meningsmålingerne som sagt også har klaret sig fint. Her kan det også anbefales, at man læser Martin Vinæs Larsens opdaterede arbejdspapir omkring kvaliteten af meningsmålingerne. Han giver en god historisk gennemgang af kvaliteten af meningsmålingerne over tid i en dansk kontekst.
Metodeovervejelser
Vi kunne være stoppet her, men det giver god mening at gå mere i dybden med nogle af de metodiske overvejelser, vi har gjort os i forhold til snittet. Kvalitetsvægtede gennemsnit af meningsmålinger varierer primært i forhold til kompleksitet. Et vægtet gennemsnit kan gå fra at være et simpelt aritmetisk gennemsnit af de seneste meningsmålinger til komplicerede statistiske modeller, der estimerer en lang række parametre og forsøger at tage højde for en lang række begrænsninger med meningsmålingerne.
Hvor avanceret et snit, der er tale om, handler primært om, hvor meget data vi har adgang til, samt hvor stor variation, vi antager, at der er i kvaliteten af disse data. I en amerikansk kontekst er der eksempelvis meget data og stor variation i kvaliteten af meningsmålingerne, hvorfor der ofte anvendes mere komplicerede modeller (se eksempelvis metoden bag FiftyPlusOne). Med andre ord giver kvantiteten af meningsmålinger anledning til at overveje kvaliteten af samme, hvilket medfører mere avancerede statistiske modeller.
Metoden bag JP-snittet er relativt simpel. Dette skyldes ikke, at vi har noget imod at arbejde med mere avancerede modeller, men fordi der ganske enkelt ikke er en åbenlys fordel ved at lave mere avancerede modeller. Der er især to grunde til, at metoden her er relativt simpel. For det første datakvaliteten i en dansk kontekst. Meningsmålingerne har over de seneste mange folketingsvalg som sagt klaret sig relativt godt, og der er ikke meget variation på tværs af de forskellige institutter. Det vil sige, at der ikke er ét eller flere analyseinstitutter, der systematisk klarer sig dårligere end andre analyseinstitutter. Hvis det var tilfældet, ville det give mening at overveje, hvor meget de forskellige institutter skulle have betydning i et snit (og om de overhovedet skulle inkluderes eller ej).
For det andet er der spørgsmålet om kvantiteten af data i en dansk kontekst. Der er relativt få meningsmålinger op til danske folketingsvalg når man sammenligner med andre lande (herunder især USA) og med tidligere folketingsvalg. Det er således begrænset, hvor meget ekstra en avanceret statistisk model kan give, som en simpel model ikke kan levere. I en lang periode op til valget var der kun ugentlige målinger fra Voxmeter og en måling hist og her fra henholdsvis Epinion og Verian (og som sagt desværre ingen målinger fra Megafon, der kan bruges i et snit).
Ved de tidligere valg i 2019 og 2022 brugte jeg en Bayesiansk model til at estimere opbakningen til partierne. Det er jeg gået væk fra dette valg. Der er to grunde til dette. For det første kørte jeg en række forskellige modeller, og de gav noget nær identiske resultater (tæt på 100% identiske resultater for flere partier), og hvor de ikke gav de samme resultater, var der ingen indikation på, at det skyldtes, at en mere avanceret model var mere præcis. For det andet tog det lang tid at køre de pågældende modeller. Vi implementerede derfor et relativt simpelt setup, hvor det kun tager et par sekunder at køre snittet, når en ny meningsmåling er tilføjet. Den primære praktiske forskel fra 2022-valget til i dag er at jeg stod for at indsamle alle meningsmålinger selv og køre modellen og dernæst dele resultaterne med Jyllands-Posten, og i 2022 kunne det tage en god times tid at køre modellen, hvilket var et mareridt, især når det skulle gøres flere gange på en dag. Som ved tidligere valg kører snittet uden problemer i R, og jeg er pænt tilfreds med hvor simpel og effektiv scriptet endte med at være.
Rent statistisk estimeres en generaliseret additiv model, der udjævner udsving over tid og estimerer opbakningen til de enkelte partier dag for dag, hvor vi også tager systematiske forskelle mellem institutter i betragtning. Det primære arbejde i at undersøge, hvor godt snittet kan være, har været i forhold til at sørge for, at nye meningsmålinger får større betydning for, hvor partierne står i dag, men at det ikke kun er de seneste meningsmålinger, der har en betydning.
Hver meningsmåling får i snittet en vægt, der er en funktion af to parametre: stikprøvestørrelsen ($n_i$) og hvor mange dage siden det er, at dataindsamlingen blev afsluttet ($t_i$). Stikprøvestørrelsen sikrer, at meningsmålinger med flere respondenter har større vægt. Her tager vi dog kvadratroden af stikprøvestørrelsen ($\sqrt{n_i}$). Dette fordi en meningsmåling med 2.000 respondenter ikke nødvendigvis er dobbelt så god som en meningsmåling med 1.000 respondenter (læsere med kendskab til forholdet mellem stikprøvestørrelse og statistisk usikkerhed vil vide, at betydningen af en større stikprøve bliver mindre, jo flere respondenter vi har).
Vi bruger antallet af dage siden meningsmålingen blev foretaget til at reducere vægten for ældre meningsmålinger. Vi opererer her med en minimumsvægt, $w_{\min}$, som sikrer, at ældre målinger aldrig mister deres betydning helt. Dette gør gennemsnittet mere stabilt historisk, men stadig mere responsivt til nyere målinger. Vi opererer som det næste med en halveringstid, $h$. Halveringstiden betyder, at vægten af en måling halveres efter en given periode. Jeg har arbejdet med forskellige minimumsvægte ($w_{\min}$) og forskellige halveringstider ($h$), og når jeg kørte det på en række tidligere folketingsvalg virkede den nuværende fremgangsmåde fortræffeligt. Jeg var dog også bekymret for potentiel overfitting, så mere arbejde kan med sikkerhed blive lagt i at bruge data fra tidligere valg til at optimere snittet fremadrettet.
Snittet tager udgangspunkt i et datasæt jeg har indsamlet og vedligeholdt i over 15 år, og som indtil 2022 var frit tilgængeligt offentligt. Jeg ville absolut ikke have noget imod at datasættet stadig er frit tilgængeligt, men det er selvsagt ikke en risiko jeg ønsker at tage. Generelt har jeg en stærk præference for at minimere sandsynligheden for, at advokater tager kontakt til mig.
Det er snart 13 år siden at jeg skrev mit første indlæg med nogle overvejelser omkring kvalitetsvægtede gennemsnit og statistisk usikkerhed, og jeg har over årene skrevet utallige indlæg omkring styrker og svagheder ved vægtede snit. Jeg er sikker på, at snittet kan forbedres, og det er stadig godt at have et kritisk perspektiv på det vægtede snit.
For og imod snittet
Der er som altid en række udfordringer forbundet med meningsmålingerne og kvalitetsvægtede gennemsnit. Jeg skal her komme ind på de vigtigste kritikpunkter, men lad mig begynde med et kritikpunkt, som jeg er uenig i, og som jeg under normale omstændigheder ikke engang ville tænke over, kunne være et seriøst argument imod kvalitetsvægtede gennemsnit. Udgangspunktet er en kommentar i Jyllands-Posten omkring begrænsninger ved JP-snittet, hvor det pointeres, at kvalitet er vigtigere end kvantitet.
Det er for mig at se et mærkeligt argument imod snittet og det arbejde der er lagt i det, at det skulle prioritere kvantitet over kvalitet. Dette især når det sker med en henvisning til ikke-repræsentative enkeltmålinger (for en udførlig diskussion af udfordringerne med Literary Digest-målingen i en moderne kontekst, kan jeg varmt anbefale bogen Polling at a Crossroads af Michael A. Bailey). Det er korrekt at enkeltmålinger kan være bedre end vægtede gennemsnit (en pointe jeg har fremført utallige gange over årene), men det er ikke et godt argument i og for sig selv at fokusere på enkeltmålinger (for et par år siden legede jeg sågar med idéen om, at jo større sandsynligheden er for, at et vægtet snit tager fejl, desto mere har vi brug for et vægtet snit).
Der er tre problemer med denne argumentation. For det første er der ikke tale om en enten-eller situation, hvor du skal vælge mellem enkeltmålinger eller kvalitetsvægtede gennemsnit. Jeg har igen og igen argumenteret for, at de kan og bør supplere hinanden. Jeg køber derfor ikke distinktionen mellem kvalitet (gode enkeltmålinger) og kvantitet (vægtede gennemsnit). Der er politiske nørder, der udelukkende konsumerer vægtede gennemsnit og plæderer for, at det er den eneste rigtige måde at se på ændringer i opbakningen til partierne, men jeg har svært ved at se, hvorfor dette er et problem for et vægtet gennemsnit i og for sig selv.
For det andet er det meget sparsommeligt med information fra analyseinstitutterne om, hvordan meningsmålingerne er foretaget. Forsøg gerne at få et overblik over deres metoder og kvaliteten af deres paneler, og du vil blive overrasket over, hvor lidt information, der er tilgængelig. Jeg har stor sympati for ideen om at konsumere de bedste målinger frem for et vægtet snit af alle målinger, men hvordan kan du helt præcist vide, hvilke målinger, der er bedst? Der er mig bekendt ingen evidens for i en dansk kontekst, at bestemte kvalitetsindikatorer hos institutterne, der er offentligt tilgængelige, korrelerer med deres præcision.
For det tredje er det min opfattelse, at den politiske dækning stadig er præget langt mere af enkeltmålinger end vægtede gennemsnit. I det omfang det giver mening at tale om en distinktion mellem kvantitet og kvalitet, vil jeg tværtimod argumentere for, at når det kommer til kvantiteten af dækningen af meningsmålinger, har enkeltmålingerne stadig en klar styrke i forhold til at præge mediebilledet (for en teoretisk argumentation om hvorfor og en empirisk test af dette kan jeg stadig anbefale min bog skrevet sammen med Zoltán Fazekas).
Ser man på meningsmålingerne generelt betragtet under valgkampen, er det min vurdering, at der skete mindre forskydninger i løbet af valgkampen, og de store ændringer i vælgerhavet i løbet af et par uger udeblev. Det kræver derfor ikke de store færdigheder at identificere artikler fra valgkampen, der byggede på enkeltmålinger, som fik stor omtale på grund af, at de afveg fra et vægtet gennemsnit (og ikke på trods af). Dette er som regel nemmere at diskutere nu efter vi kender valgresultatet, og det er så godt som umuligt at se, at der er tale om en outlier, hvis du blot følger dækningen uden et vægtet snit.
Lad os tage to eksempler fra Berlingske. I denne artikel fra 11. marts kunne Berlingske rapportere, at "Mette Frederiksen stormer frem i spritny måling og sikrer rødt flertal". Dette var selvfølgelig en stor nyhed, men der er intet der tyder på, at rød blok har stået til mere end 50% af stemmerne i løbet af valgkampen, med undtagelse af netop denne ene måling (og hvis man tager den statistiske usikkerhed på blokniveau i betragtning, var der ikke sikret et rødt flertal). Det var også den eneste meningsmåling i løbet af valgkampen, der havde Socialdemokratiet tæt på 24% af stemmerne.
En uge senere, den 18. marts, kunne Berlingske i en artikel, på baggrund af en ny meningsmåling, nu formidle at "Venstre stormer frem med bedste resultat i hele regeringens levetid". Dette blev set som en "eksplosiv måling". I denne meningsmåling fik Venstre 12% af stemmerne, og ingen anden måling i løbet af valgkampen gav Venstre 12% af stemmerne (endsige 11% af stemmerne). Hvis du således udelukkende følger valgkampen på baggrund af enkeltmålinger, kan du - inden for det samme medie med samme institut i løbet af en uge - gå fra, at Socialdemokratiet stormer frem, til at Venstre stormer frem. Et snit vil - i min optik - korrekt mane til besindighed og sige, at der nok ikke er evidens for, at nogle af de respektive partier har stormet hverken frem eller tilbage i løbet af få dage.
Jeg erfarer dog, at TV 2 stadig er de værste i forhold til at dække enkeltmålinger. TV 2 dækker meningsmålingerne i et parallelunivers, hvor ingen andre meningsmålinger eksisterer, og kun deres egen forkerte tolkning af meningsmålingerne præsenteres for deres læsere. Det samme ser vi som bekendt hos andre medier, men TV 2 er i min optik de værste af slagsen. Hvis du udelukkende konsumerer meningsmålinger via TV 2, bliver du i bedste fald ikke klogere på meningsmålingerne og i værste fald misinformeret. Det sørgelige er, at det ikke kan forklares med inkompetence. Det skyldes derimod bevidst misinformation, der på ingen måde harmonerer med grundlæggende journalistiske principper. Jeg ved fra erfaring over årene, at deres politiske journalister kender til alle fordelene ved kvalitetsvægtede gennemsnit, potentielle udfordringer med huseffekter osv. De går dog langt mere op i at facilitere brugen af alle midler, juridiske og praktiske, til at reducere kvaliteten af den politiske dækning, hvis det kan give mere omtale til deres egne målinger.
For det mest åbenlyse eksempel fra denne valgkamp kan jeg anbefale denne artikel, hvor TV 2 misinformerer deres læsere om, hvordan man kan bruge meningsmålinger ved et valg. Problemet er ikke alene, at de her udelukker at rapportere om, at der findes kvalitetsvægtede gennemsnit af meningsmålingerne, men at de også præsenterer en fundamentalt misvisende beskrivelse af, hvordan vi skal forstå den statistiske usikkerhed i målingerne. I artiklen præsenteres man for følgende beskrivelse af, hvorfor vi har den statistiske usikkerhed: "Usikkerheden kan blandt andet komme fra, at vælgerne simpelthen skifter holdning, inden de skal sætte deres kryds ved valget – og dermed efter de har svaret på det politiske indeks." Det er på ingen måde korrekt. Selv hvis du har lavet verdens bedste meningsmåling uden nogle målefejl og uden at vælgerne skulle skifte holdning, har du stadig en statistisk usikkerhed. Igen, hvis du udelukkende følger dækningen af meningsmålingerne hos TV 2... held og lykke.
Det andet kritikpunkt af vægtede gennemsnit er, at de vægtede gennemsnit er gratister. De anvender data der på ingen måde er gratis at fremstille, og hvis vi kun konsumerede kvalitetsvægtede gennemsnit og ikke enkeltmålingerne, ville der til sidst ikke være nok data til et vægtet snit. Dette er et kritikpunkt jeg har meget stor sympati for, og et kritikpunkt jeg finder langt mere relevant at diskutere. Der er ingen tvivl omkring, at vægtede gennemsnit på den ene side tjener et vigtigt formål til at nuancere den politiske dækning, men at de også er afhængige af, at der netop foretages enkeltmålinger. Derfor har jeg også altid gjort et stort arbejde ud af at kredittere og henvise til enkeltmålingerne, og sågar argumenteret for, at vi aldrig blot skal kigge på vægtede gennemsnit, men også de respektive målinger, der indgår i snittet.
Jeg ser hver enkelt meningsmåling som en brik i et puslespil, og jo flere brikker vi har, desto bedre et samlet billede kan et vægtet snit vise. Men hvis fokus på det samlede billede gør, at incitamentet til at indsamle brikker reduceres, står vi med et dårligere samlet billede. Igen ser jeg ikke dette som et spørgsmål om enten-eller, men at enkeltmålinger tjener et andet formål end vægtede snit, og de to bør kunne sameksistere. Med andre ord ser jeg det ikke som en begrænsning ved et vægtet snit i og for sig selv, men et vigtigt aspekt at forholde sig til i et moderne medielandskab.
Der var også en del fokus på JP-snittet i løbet af valgkampen, og jeg så flere medier lave tophistorier på baggrund af snittet. Ekstra Bladet kunne eksempelvis bringe følgende historie på baggrund af snittet, der viste, at LA var større end Venstre.

Min bekymring med denne og lignende historier var, at snittet potentielt kunne være et statistisk artefakt, der ikke harmonerede med, hvad enkeltmålingerne viste. I dette tilfælde analyserede jeg de respektive enkeltmålinger og tjekkede flere aspekter af snittet, og jeg havde det fint med konklusionen om, at LA på dette tidspunkt sandsynligvis var større end Venstre. Udfordringen er dog, at den statistiske usikkerhed reduceres i snittet, så hvad der måske ikke er belæg for i en enkeltmåling, kan der pludselig være statistisk belæg for i et vægtet snit. Her mener jeg bestemt, at medierne har et ansvar for ikke alene at formidle et vægtet snit, men også fokusere på de tendenser, man ser i enkeltmålingerne, som rummer vigtige forbehold.
Et vægtet snit som JP-snittet er en god ressource, men det er ikke den eneste ressource, og det er som sagt vigtigt at huske på, at det ikke er bedre end de enkeltmålinger, det bliver fodret med. Derfor er det vigtigt ikke blot at se på estimaterne fra dette og lignende snit, men også hvad målingerne fra de forskellige institutter viser.
Snittet i fremtiden
Der er flere forhold, der kan forbedres ved snittet fremadrettet. For det første vil det være godt at have en bedre model for den statistiske usikkerhed i snittet. Konkret er min bekymring, at den statistiske usikkerhed er for lille i snittet, og jeg vil foretrække at kalibrere den statistiske usikkerhed med udgangspunkt i præcisionen ved tidligere folketingsvalg. Jeg skrev et længere indlæg i 2024 omkring mine idéer her, men jeg er ikke kommet videre med dette.
For det andet vil det også være godt at have usikkerhed for mandattallene. Snittet giver nu blot mandattal på baggrund af opbakningen i snittet, men det vil også være godt at have en idé om, hvor stor usikkerhed der er her. YouGov arbejdede ved dette valg med en Looped Stratified Simulation model, og deres arbejde ser interessant ud i forhold til også at give bud på, hvor mange mandater de forskellige partier kan få. Det kræver ikke store ændringer i opbakningen til partierne i procent, før det får implikationer for antallet af mandater, og det vil være rart at have en idé om, hvor stor usikkerhed, vi opererer med.
For det tredje er jeg i tvivl om, hvordan jeg skal forholde mig til, at snittet kan opdateres bagudrettet. Et hypotetisk eksempel kan hjælpe her. Hvis to meningsmålinger giver et parti en opbakning på 10% den 28. februar, vil et snit give partiet en opbakning på 10% den pågældende dag. Hvis der kommer en tredje meningsmåling 1. marts, der giver partiet 20%, vil det vægtede snit også mene, at opbakningen til partiet sandsynligvis var større end 10% den 28. februar. Med andre ord tager snittet udgangspunkt i al data til at give et bud på, hvor stor opbakningen til partierne har været over tid, og tallene kan ændres bagudrettet. En løsning kan være at "låse" estimaterne, så opbakningen aldrig vil ændre sig, men jeg er ikke overbevist om, at dette er den bedste løsning. I praksis er det ikke en udfordring, da nye målinger sjældent rykker sig meget, og dermed ligeledes ikke har implikationer for opbakningen til partierne bagudrettet, men det er stadig et aspekt, der er værd at reflektere nærmere over og forholde sig til.
Der er med andre ord nok at forholde sig til for snittet fremadrettet. Spørgsmålet er primært, om jeg har motivationen til at indsamle, analysere og diskutere meningsmålingerne. Det har fungeret fint ved dette valg da Jyllands-Posten har stået for at opdatere snittet med data og alt har kørt ganske automatisk, men det ville være perfekt, hvis nogen kunne stå for det videre arbejde med at forbedre snittet. Det er som regel mange af de samme pointer, jeg gentager igen og igen, og min interesse ligger primært andetsteds disse år. Jeg har ligeledes meget lidt motivation til at arbejde med noget, der potentielt kunne føre til juridiske trusler om krav om at betale fem til sekscifrede beløb for brugen af deres meningsmålinger.
Dette skal dog ikke overskygge fra det faktum, at jeg har haft et fortræffeligt samarbejde med Jyllands-Posten over årene, og især med Nikolaj Rytgaard og Boy Repenning, der med deres kompetencer står for, hvad der i min optik er en rigtig god dækning af dansk politik. Jeg ville med andre ord med sikkerhed ikke have været involveret i et snit af meningsmålingerne ved dette valg, hvis det ikke var for dem.
JP-snittet klarede sig fint, og det er blot symptomatisk for det faktum, at meningsmålingerne generelt klarede sig godt. Nogle målinger kunne have været bedre, og målingerne kunne have ramt bestemte partier bedre, men overordnet betragtet var folketingsvalget 2026 et godt valg for meningsmålingerne.